
Shan Yang
Researcher · RL Post-Training & Agentic Reasoning
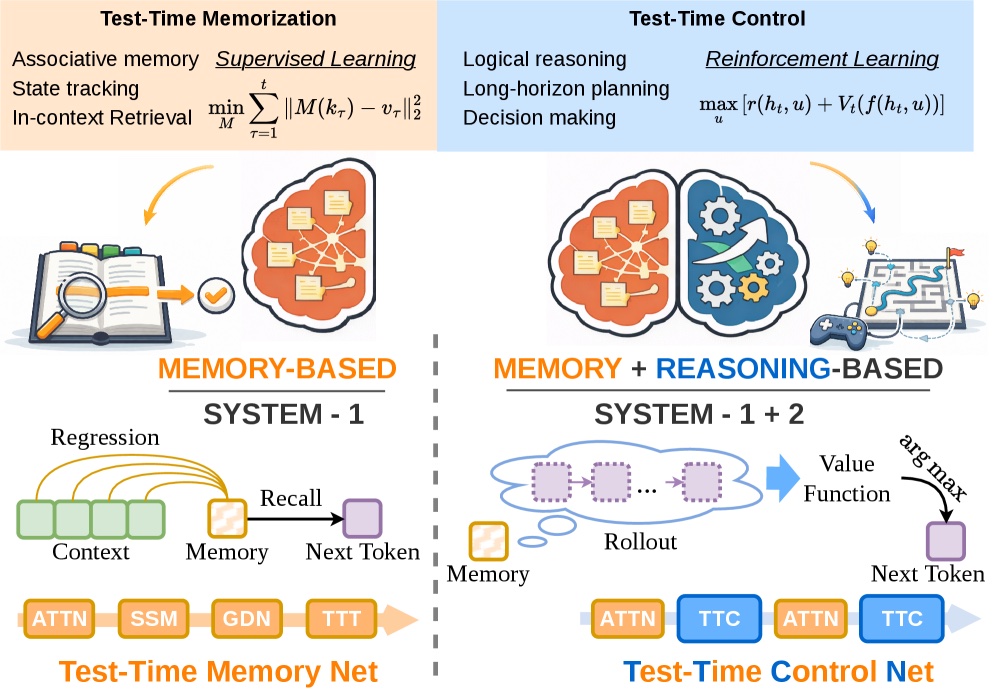
I work on RL post-training — models that reason and use tools reliably. My focus is the unglamorous half of the stack: audited training data, hard evaluation benchmarks, reward design, and RL recipes that survive real-world deployment. Physics reasoning is where I proved it out (Physics-R1); I'm now extending it to agentic tool-use and reward hacking.
Currently Staff Applied Scientist at Adobe Foundry, building custom generative foundation models for enterprise customers (SFT, DPO, RL, with data curation as the main lever). Previously Tech Lead at Amazon Video Search (multimodal search + RL post-training, shipped to customers) and GenAI Live Action Studio, and Senior Research SDE at Google Research (multi-modal modeling, AIST++). PhD from UNC-Chapel Hill with Prof. Ming C. Lin on learning physical parameters from video.
Currently exploring: tool-use RL and reward hacking in agents (Physics-R2, in preparation).
Latest

Physics-R1: An Audited Olympiad Corpus and Recipe for Visual Physics Reasoning
Visual physics reasoning for vision-language models: a 2,434-record audited training corpus, a 500-question novel-source olympiad benchmark (PhysOlym-A), and an RL recipe that pushes SOTA on visual physics reasoning at the 7B scale. All artifacts open.
Selected Publications
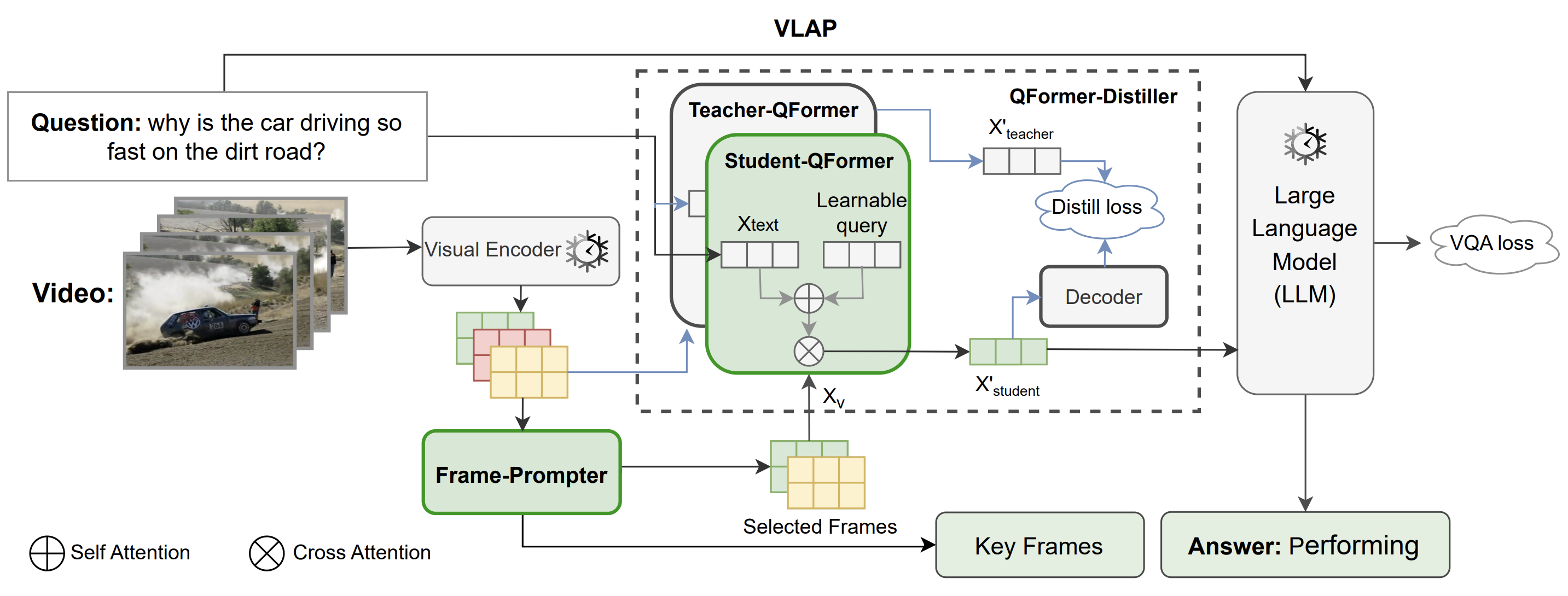
VLAP: Efficient Video-Language Alignment via Frame Prompting and Distilling for Video Question Answering
ECCV 2024

Show all publications

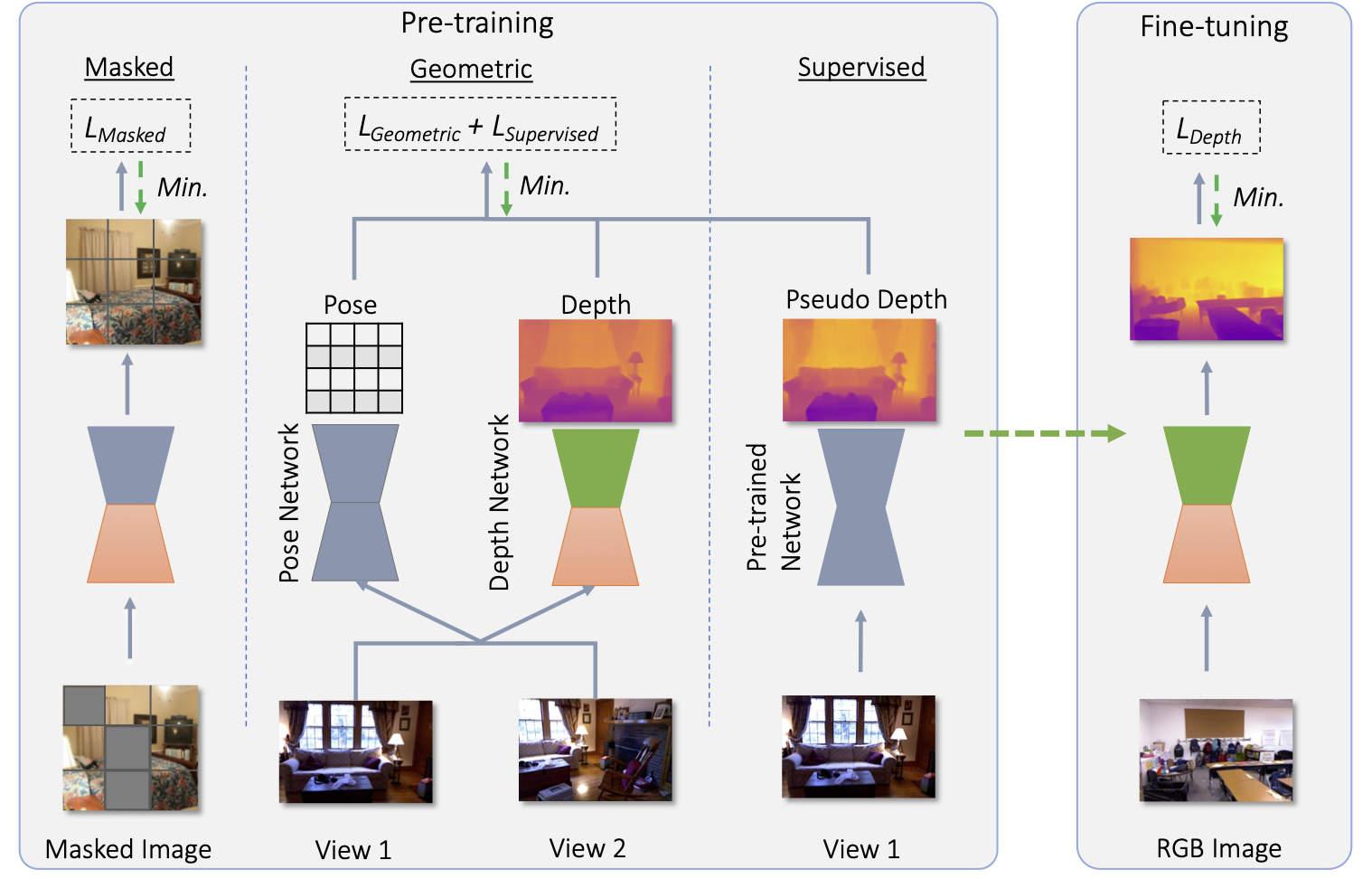
MeSa: Masked, Geometric, and Supervised Pre-training for Monocular Depth Estimation
NeurIPS 2023 Workshop SSLTheoryPractice
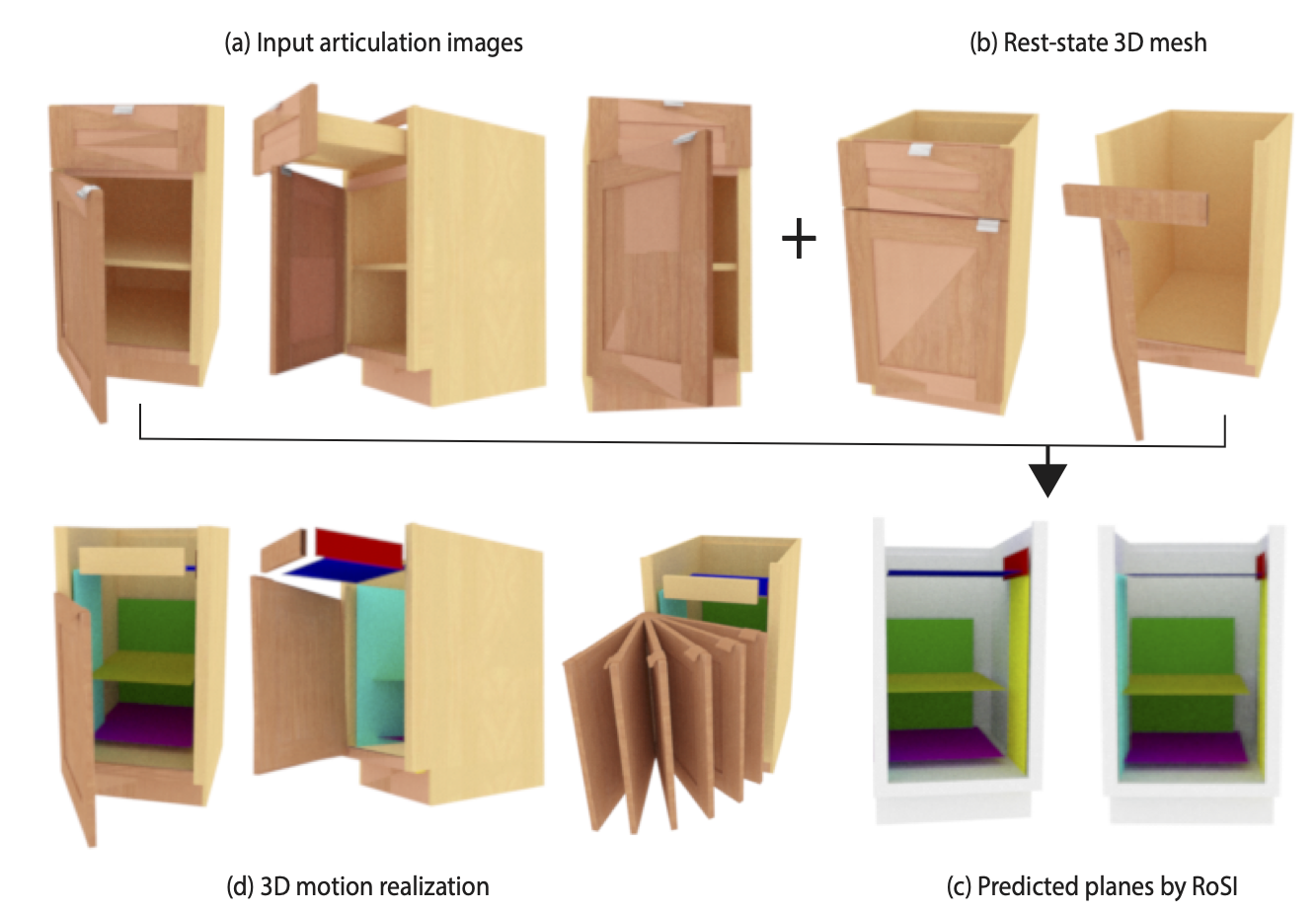
Optical Mouse: 3D Mouse Pose From Single-View Video
CVPR 2021 (CV4Animal Workshop)


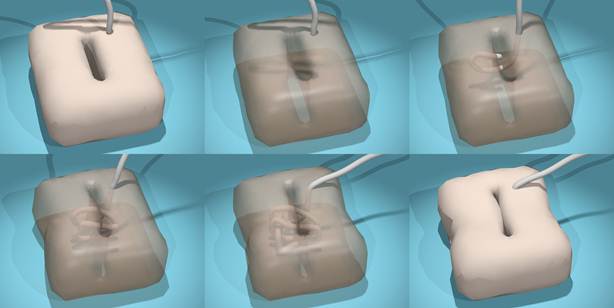
Real-time Simulation for Buried Suture
CARS 2012
Open Source & Releases
Dataset · Hugging Face
Physics-R1 Corpus
2,434-record audited training corpus for visual physics reasoning, with provenance and license audit.
Benchmark · Hugging Face
PhysOlym-A
500-question novel-source olympiad benchmark for evaluating visual physics reasoning in VLMs.
Dataset · Hugging Face
PhysDojo Annotations
11.6K episodes of physics-grounded video annotations for world-model training.
Code · GitHub
AIST++ Dataset API
Loaders and tooling for the AIST++ 3D dance dataset (from AI Choreographer, ICCV 2021).
Project
Lumi Research Manager
AI-powered research project manager with pixel-art agent teams (Scout, Theorist, Architect, Coder).
Notes · GitHub
RL Learning Log
Personal log of learning reinforcement learning — notes, experiments, and insights.